A Bit on Google's TPUs


Here is a visual explanation of how Google’s Tensor Processing Units (TPUs) work.
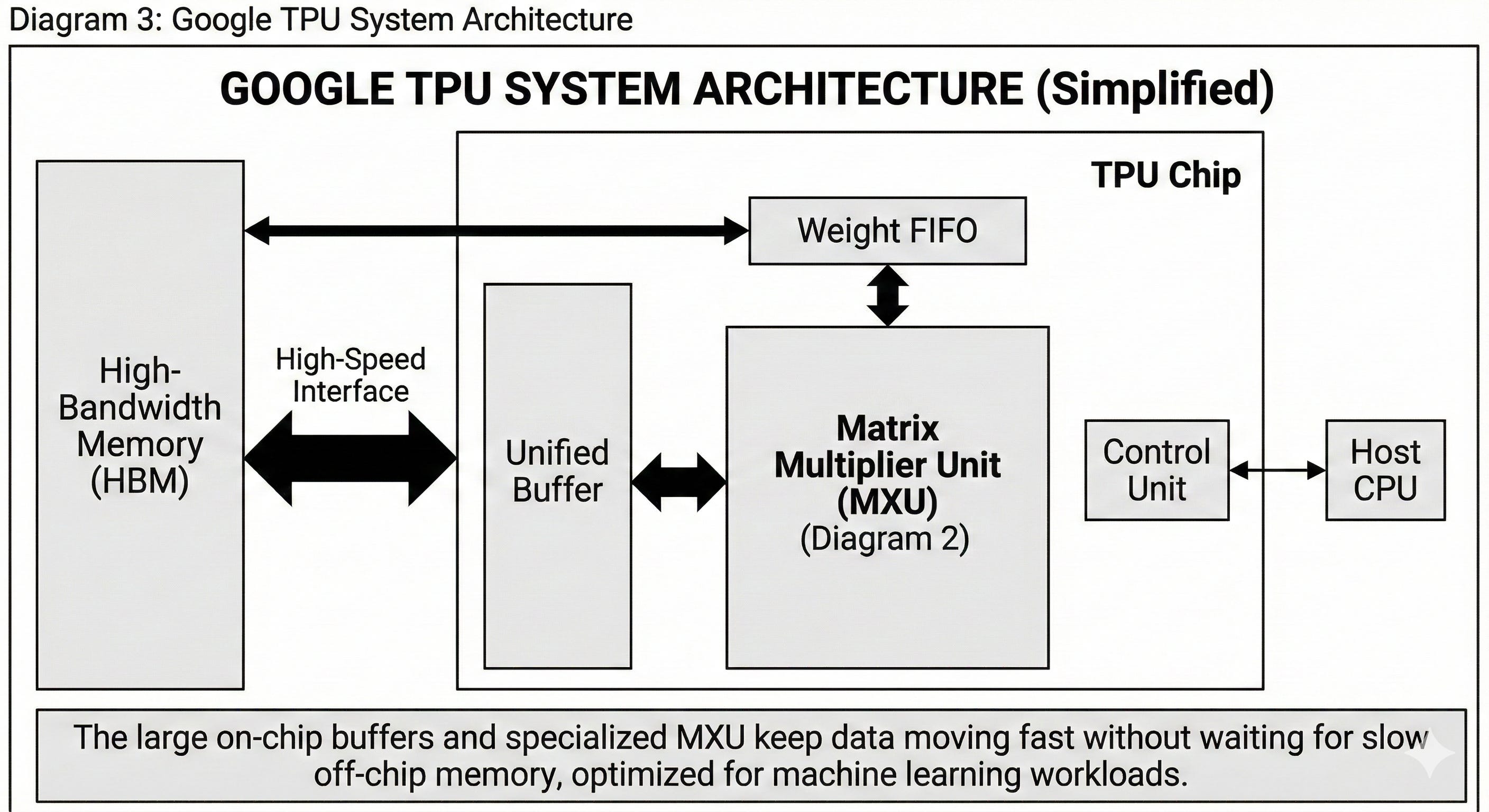
1. The Problem: The Memory Bottleneck
Traditional CPUs and GPUs are designed for general-purpose computing. When they perform the massive number of matrix multiplications required for machine learning, they spend a lot of time waiting for data to be fetched from memory. This “Von Neumann bottleneck” slows down the entire process.
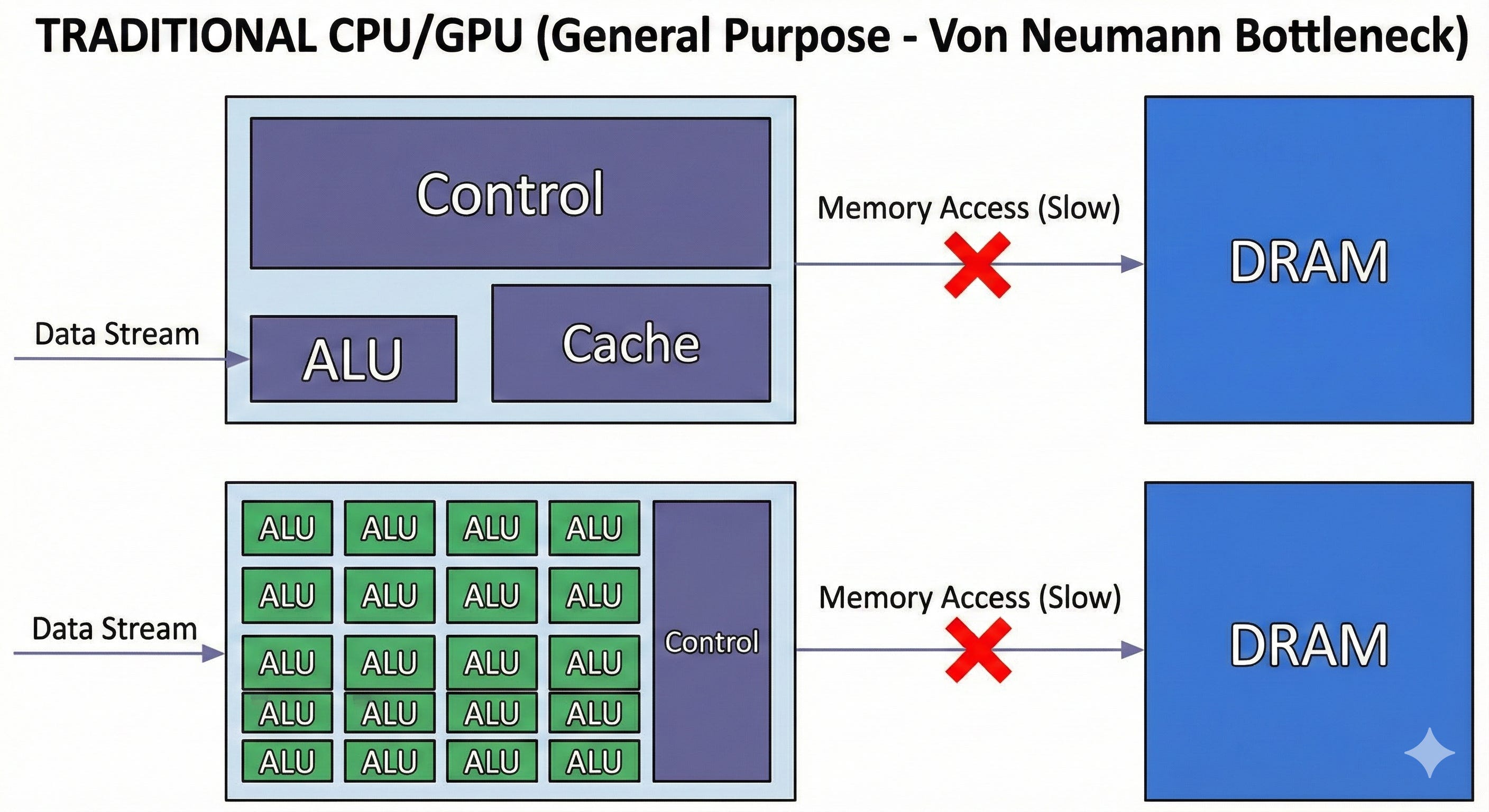
2. The Solution: The Systolic Array (MXU)
The heart of the TPU is the Matrix Multiplier Unit (MXU). Instead of fetching data for each calculation, the MXU uses a “systolic array” architecture. Data flows through a grid of processors, similar to how blood flows through the heart. Each processor performs a calculation and passes the result to its neighbor, allowing for massive parallelism and data reuse without constant memory access.
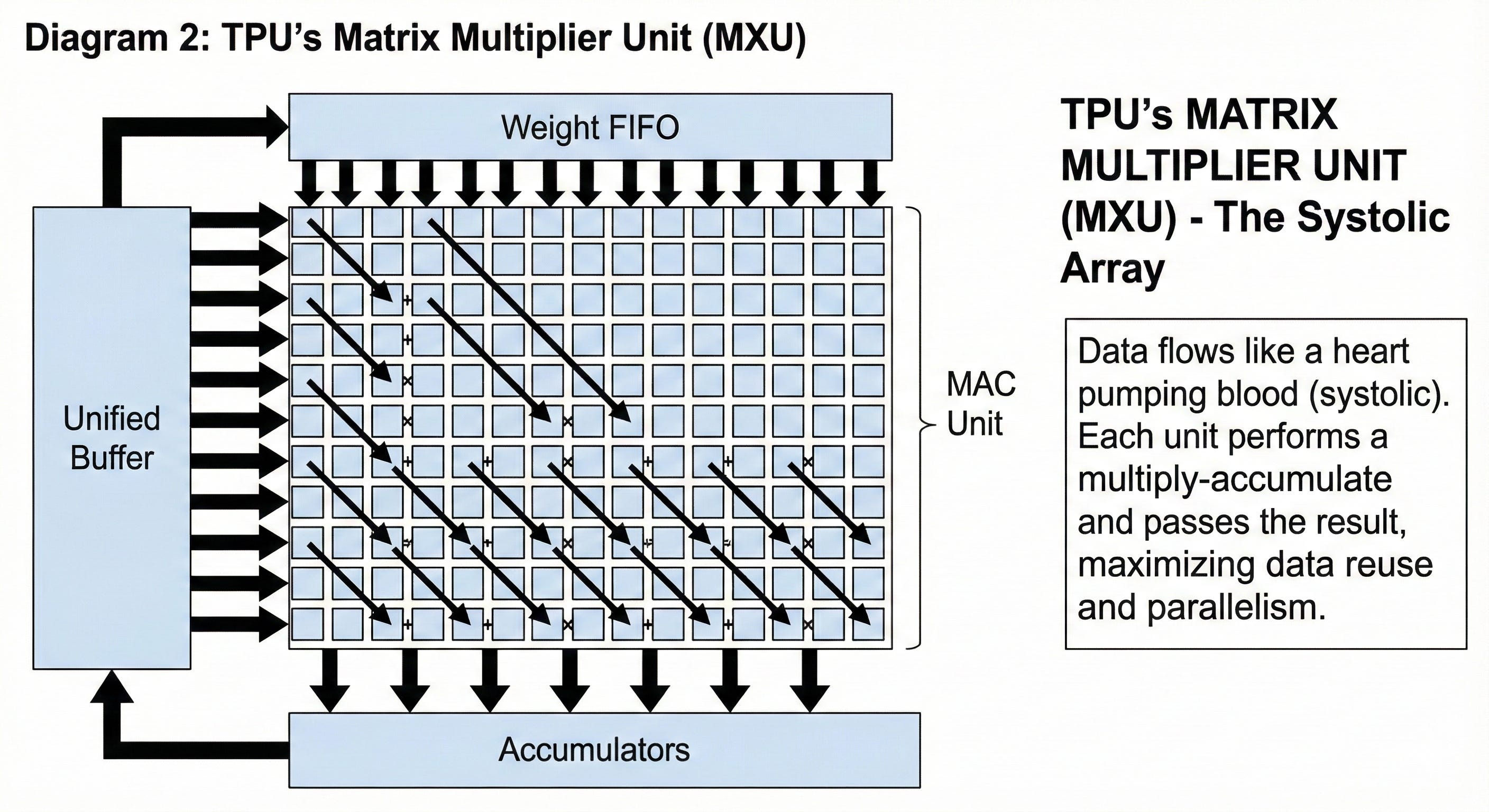
3. The Complete System Architecture
To keep the powerful MXU fed with data, the TPU has a specialized memory hierarchy. Large, high-speed buffers are built directly onto the chip, storing data close to where it’s needed. This is supplemented by external High-Bandwidth Memory (HBM). A dedicated control unit orchestrates the data flow, ensuring the MXU is always busy and not waiting for data.