
Many Enterprises Never Optimize AI Deployments because Internal AI Usage Is Low

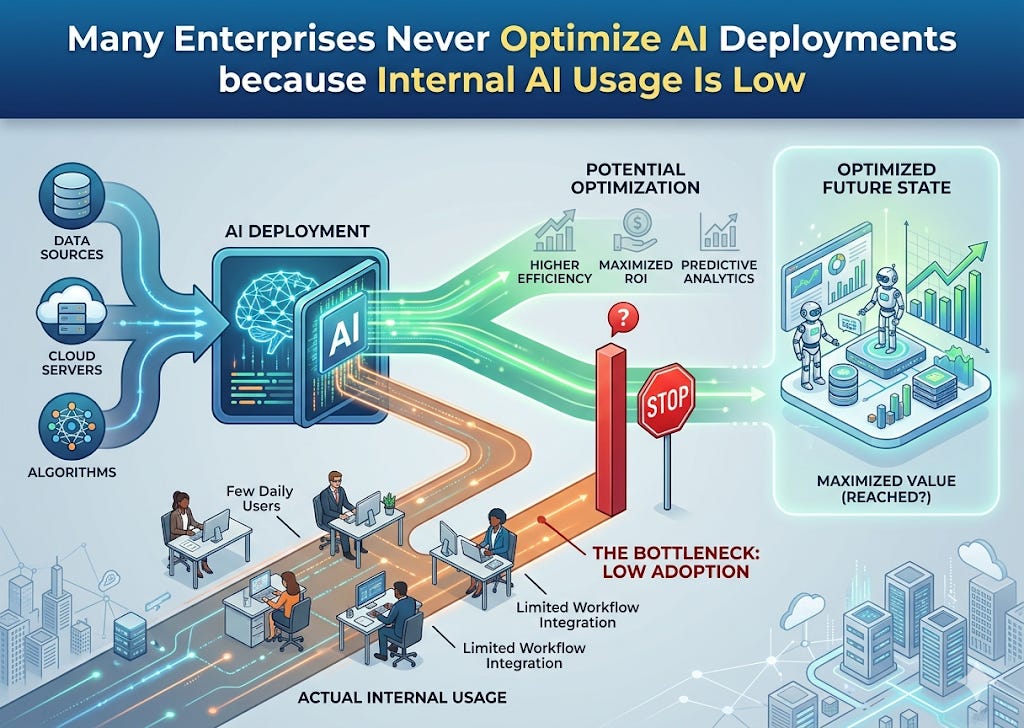
Many firms don’t know they have an AI optimization problem because not enough employees use LLMs and LLM-powered tools. It is only when employees engage with LLMs and LLM-powered tools that they notice AI behaviors and outcomes are less than optimal. This is a latent adoption-and-observability problem.
The issue is not: “The model is obviously broken.” It is: “The firm has not generated enough user interaction to reveal where the model is underperforming.”
What happens in many enterprises is:
They deploy an LLM feature;
Usage stays shallow, sporadic, or narrow;
Weak model behavior is noticed anecdotally, but not diagnosed systematically;
Because usage is limited, the pain never looks large in aggregate;
Because the pain never looks large, nobody treats optimization as urgent;
As a result, adoption stays low.
A vicious cycle
The real problem is often: under-optimization suppresses adoption, and low adoption hides the need for optimization.
These firms are burning tokens unnecessarily, are losing out on quality output, and may be losing on:
user trust
repeat usage
workflow penetration
internal AI credibility
enterprise ROI on the whole deployment
In other words, the cost is often foregone value, not just visible waste. Most firms do not realize they have an LLM optimization problem because their user base has not yet engaged deeply enough to expose it. Low adoption masks model-behavior defects, and those defects in turn prevent broader adoption.
1. Hidden failure: The model is underperforming, but the organization lacks enough interaction volume to see the pattern clearly.
2. User disappointment: Early users encounter inconsistency, ambiguity, weak answers, or bad workflow behavior.
3. Adoption drag: Users quietly stop relying on the tool, or only use it for low-stakes tasks.
4. Lost enterprise value: The company concludes the AI feature is “interesting but not essential,” when in reality it was never properly optimized.