Microsoft's AI Reorg and GRIN MoE

Could Microsoft’s recent AI reorganization be focused on smaller language models such as MSFT’s recent GRIN MoE model announcement?
Perhaps MSFT’s AI reorg strategy is for Microsoft to continue to partner with OpenAI for frontier LLMs (OAI has a big lead over MSFT’s internal language model effort) and for MSFT’s internal AI effort to focus on smaller language models such as its GRIN MoE model (GRadient INformed Mixture of Experts).
Smaller models can be deployed on phones, edge devices, cars, etc.
In the case of GRIN MoE, the model is designed to increase scalability and performance in complex tasks such as coding and mathematics.
One can imagine MSFT deploying GRIN MoE internally to help scale its coding effort using AI agents.
Similarly, I can imagine MSFT wanting to develop an AI core competency around Agentic coding to offer that capability to its Azure customers. Perhaps MSFT wants to be first-to-market around Agentic AI-based commercial grade coding?
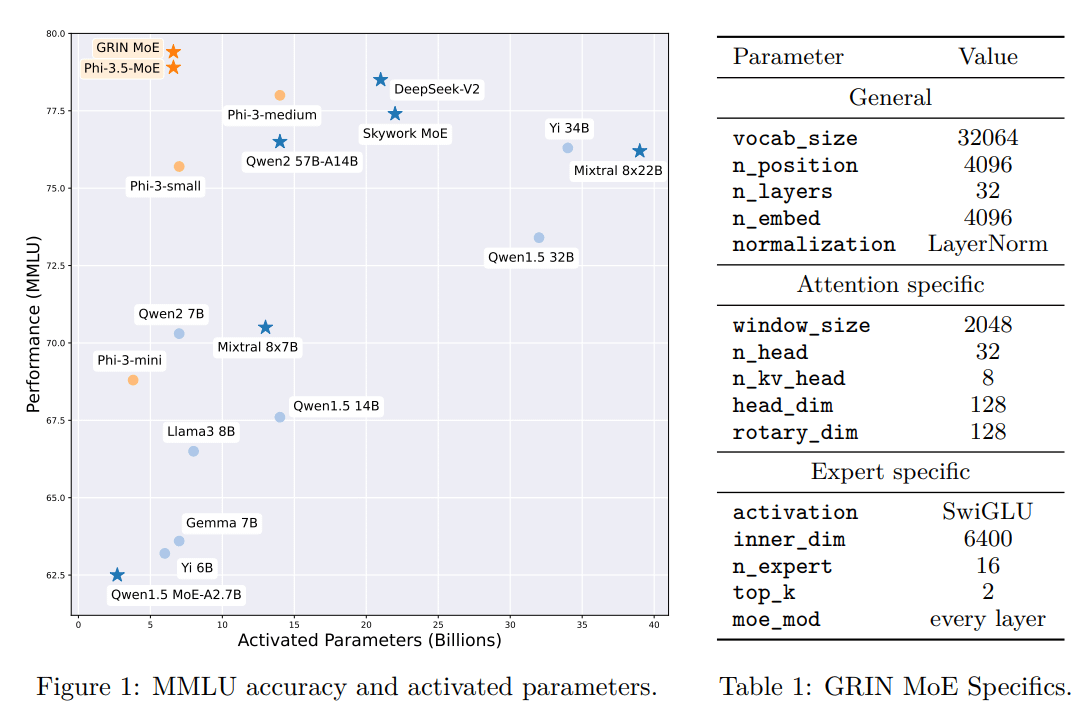
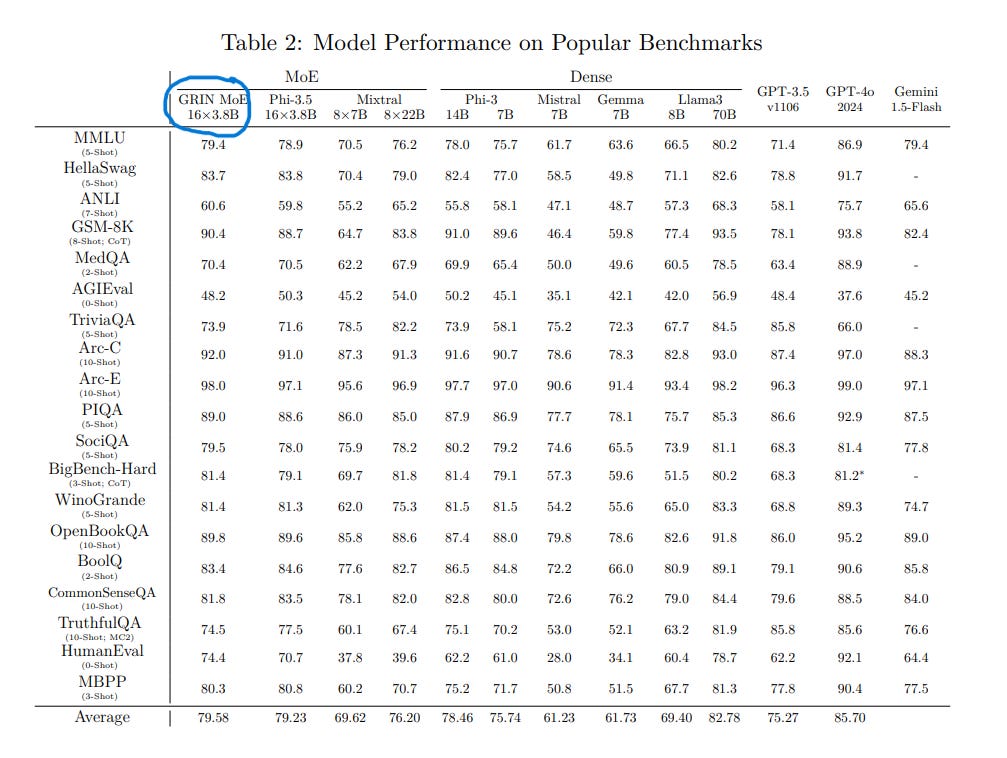
In the chart below you can see that GRIN MoE is one of the smallest models (approximately 7 billion parameters) yet has achieved the highest performance of the group.
The Mixture-of-Experts (MoE) architecture routes tasks to “experts” within the model, which enables GRIN to use less resources while achieving high-level performance. GRIN’s ability to scale efficiently makes it a better option for customer organizations that lack the infrastructure to manage frontier LLMs such as OpenAI o1, Anthropic’s Claude and Meta’s Llama open source model.
GRIN MoE challenges:
GRIN is primarily geared for English-language tasks. Performance may fall off when it is applied to other languages.
Further, GRIN MoE performs well with reasoning-heavy tasks but performs suboptimally with natural language tasks.