Reliability Is Preventing Agentic AI from Wide Adoption

There are many tasks that if we were to hand them over to an AI agent, would have to be executed flawlessly. Otherwise, we would not delegate the tasks to an AI agent. Flawless execution is not on the horizon for AI agents.
Purchasing airline tickets, renting cars, filling out tax documents, executing purchase orders, submitting insurance claims and other manual-intensive tasks are ripe for automation. However, before we hand such tasks over to LLM-powered AI agents, we require confidence that such tasks will be performed with 100% accuracy.
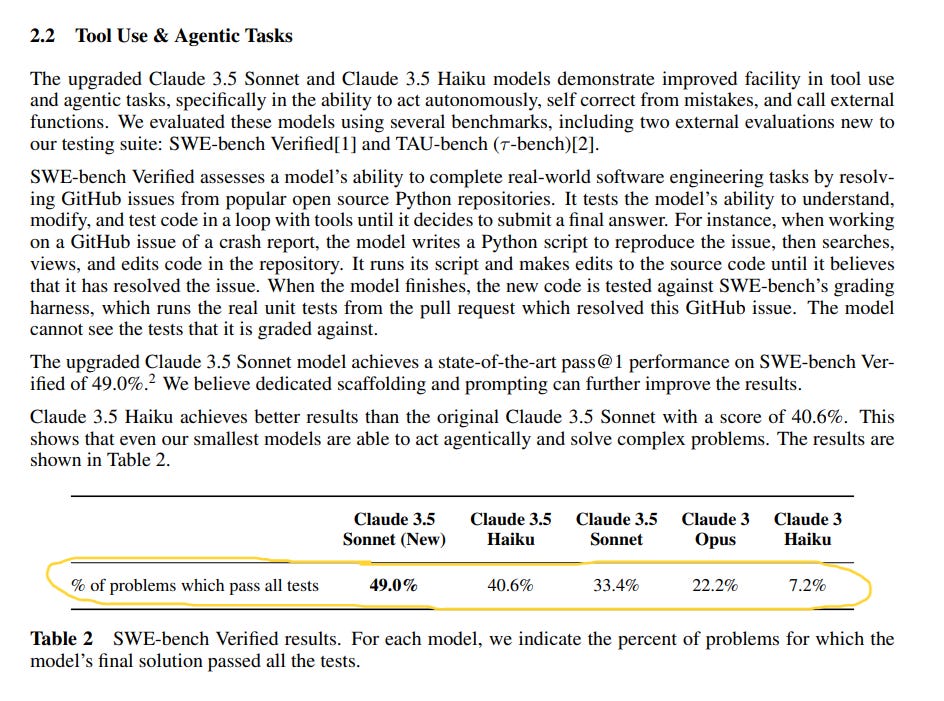
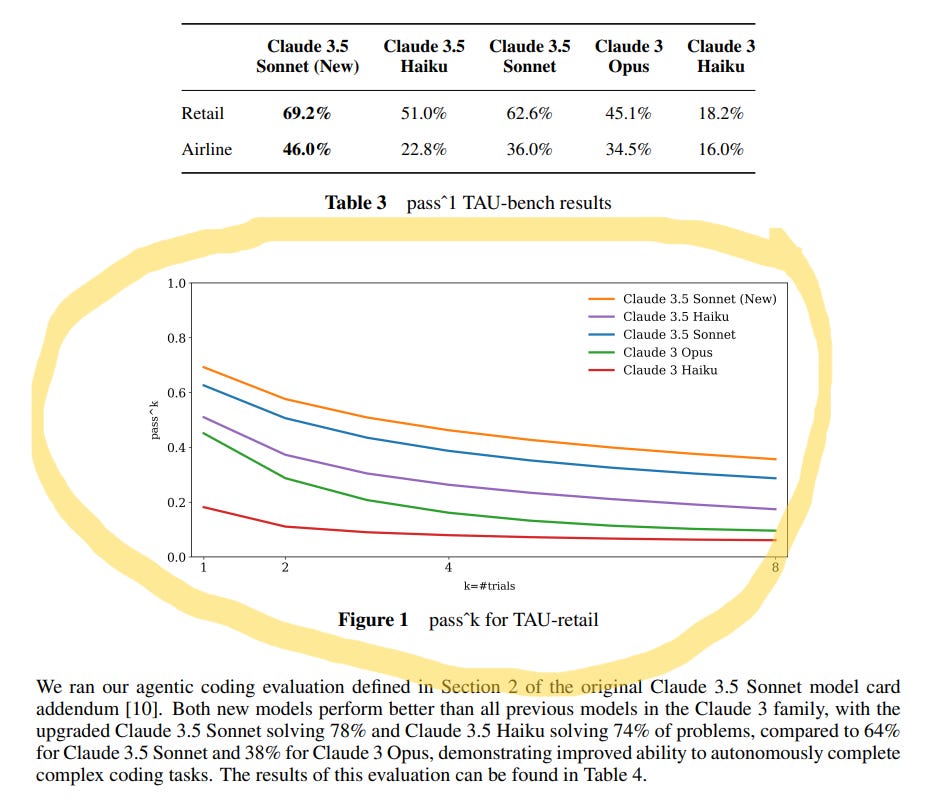
However, in reviewing the below snapshots from Anthropic’s “Claude 3.5 Haiku and Upgraded Claude 3.5 Sonnet” paper, one can see we are far removed from 100% accuracy. The paper refers to TAU bench – which evaluates AI Agents on a model’s ability “to interact with simulated users and APIs in customer service scenarios. It includes tasks in retail and airline domains – testing the model’s capacity to handle realistic multi-step customer service scenarios, follow roles and policies, and make decisions based on provided guidelines.”
Agentic models were evaluated on a series of trials. One may observe in the chart below how performance deteriorated (marked by the downward slope of the lines), as the number of trials increased. The models were tested across eight trials. Accuracy declined as the number of trials increased (retail scenario depicted in below chart). That chart needs to plot at 1.0 (100%) before we experience wide adoption of Agentic AI.