Rise of The SLMs


Small Language Models (SLMs) will proliferate over the next few years as they increasingly become embedded on devices, extending beyond horizontal productivity use cases to vertical-specific use cases.
Today you will find SLMs deployed on phones with use cases such as text-to-speech, live captioning, language translation, transcription, document search and AI-assisted writing to name a few examples. These are largely what I refer to as horizontal productivity applications.
It is easy to imagine vertical-specific use cases where SLMs deliver Gen AI capabilities deployed by a wide variety of companies for on-device use. Companies such as Ansys (ANSS), Autodesk (ADSK), Bloomberg, Cerner/Oracle (ORCL), CoStar (CSGP), Factset(FDS), J.P. Morgan (JPM), Paychex (PAYX), S&P Global (SPGI), Visa (V) and most every Enterprise Software company I can think of will leverage increasingly powerful SLMs that will generate greater output with a smaller footprint as SLMs evolve.
Many day-to-day use cases simply will not require the latest and greatest Large Language Models (LLMs), which will continue to reside in hundred billion Dollar-plus data centers rather than on-device.
I am bullish on low-cost approaches to Gen AI, especially open source approaches. Much can be achieved at low cost with an open source SLM from Meta (META) that leverages super fast inference from Groq as an example. One will not need to deploy OpenAI’s forthcoming Orion LLM built with NVIDIA’s (NVDA) expensive chip set to benefit from advanced automation.
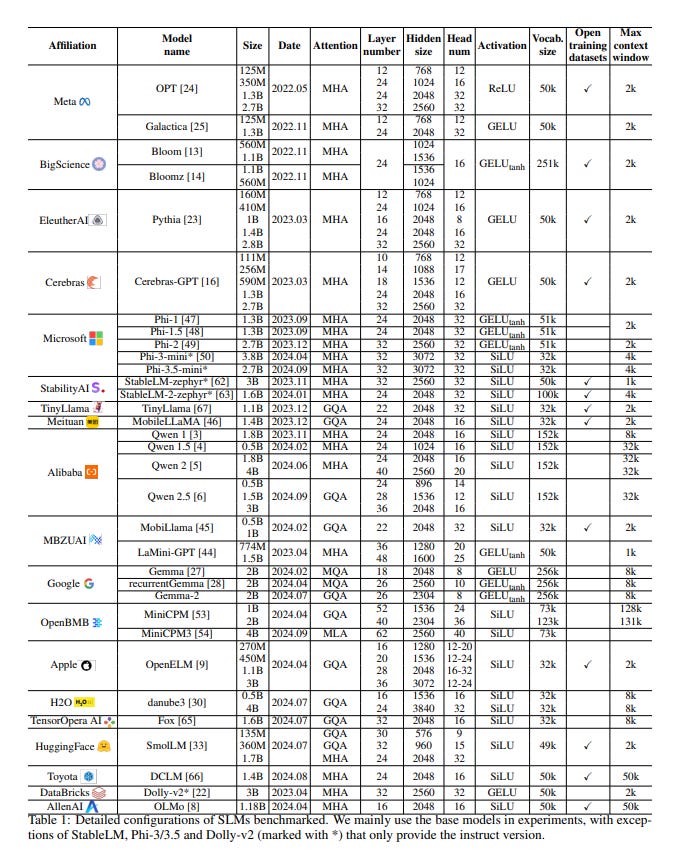
The below tables and charts are from a recent research paper that was published on September 24th of this year - SMALL LANGUAGE MODELS: SURVEY, MEASUREMENTS, AND INSIGHTS.
There is hardly a shortage of SLMs. Companies will build thousands of applications and services that will extend off of these and other SLMs.
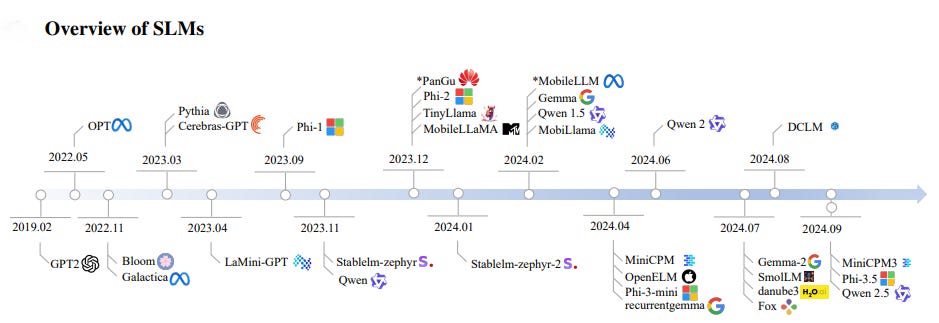
The below SLMs range in size from 111 million parameters to 4 billion parameters.
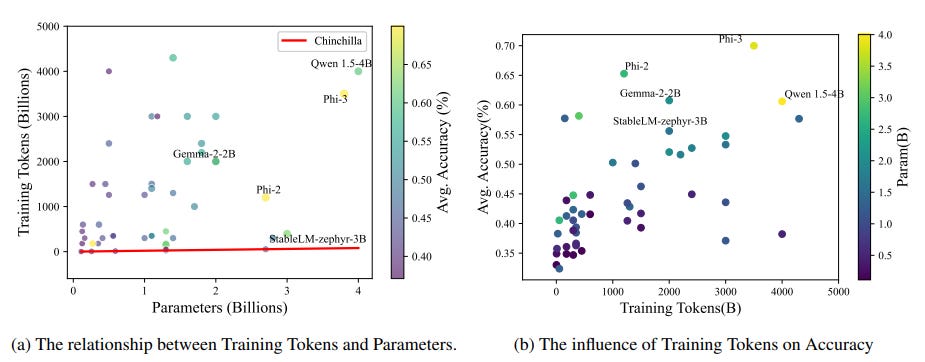
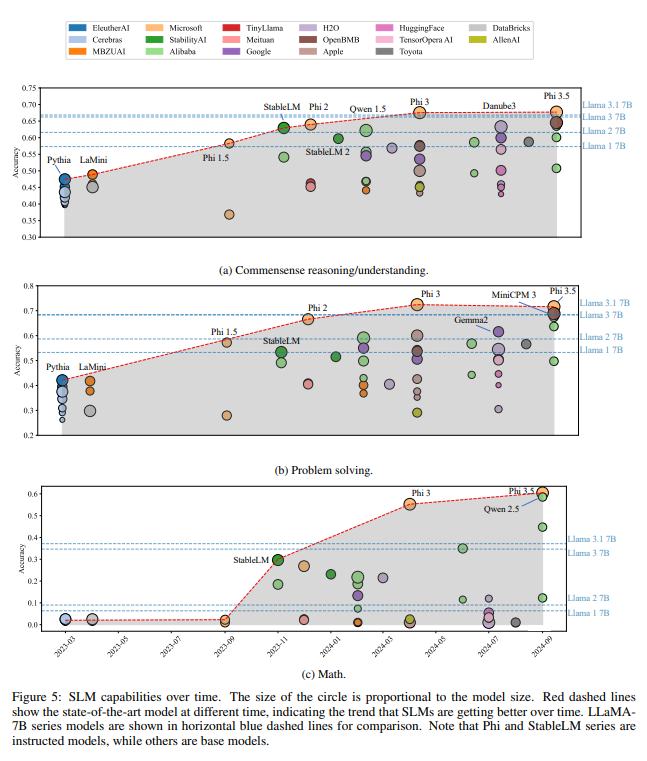
The greater the number of training tokens and parameters, the greater the accuracy. Data quality is key to training datsets as it relates to model capability.